前提 之前的一篇文章JUC线程池ThreadPoolExecutor源码分析 深入分析了JUC线程池的源码实现,特别对Executor#execute()接口的实现做了行级别的源码分析。这篇文章主要分析一下线程池扩展服务ExecutorService接口的实现源码,同时会重点分析Future的底层实现。ThreadPoolExecutor和其抽象父类AbstractExecutorService的源码从JDK8到JDK11基本没有变化,本文编写的时候使用的是JDK11,由于ExecutorService接口的定义在JDK[8,11]都没有变化,本文的分析适用于这个JDK版本范围的任意版本。最近尝试找Hexo可以渲染Asciidoc的插件,但是没有找到,于是就先移植了Asciidoc中的五种Tip。
ExecutorService接口简介 ExecutorService接口是线程池扩展功能服务接口,它的定义如下:
public interface ExecutorService extends Executor void shutdown () List<Runnable> shutdownNow () ; boolean isShutdown () boolean isTerminated () boolean awaitTermination (long timeout, TimeUnit unit) throws InterruptedException ; <T> Future<T> submit (Callable<T> task) ; <T> Future<T> submit (Runnable task, T result) ; Future<?> submit(Runnable task); <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException; <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException ; <T> T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException ;}
ExecutorService继承自Executor,主要提供了线程池的关闭、状态查询查询、可获取返回值的任务提交、整个任务列表或者执行任务列表中任意一个任务(返回执行最快的任务的结果)等功能。
Future实现的通俗原理 ExecutorService接口的扩展方法都是返回Future相关的实例。java.util.concurrent.Future(中文翻译就是未来,还是挺有意思的),代表着一次异步计算的结果 ,它提供了检查计算是否已经完成、等待计算完成、获取计算结果等一系列方法。笔者之前强调过:线程池ThreadPoolExecutor的顶级接口Executor只提供了一个无状态的返回值类型为void的execute(Runnable command)方法,无法感知异步任务执行的完成时间和获取任务计算结果。如果我们需要感知异步任务执行的返回值或者计算结果,就必须提供带返回值的接口方法去承载计算结果的操作。这些方法上一节已经介绍过,而Future就是一个担任了承载计算结果(包括结果值、状态、阻塞等待获取结果操作等)的工具。这里举一个模拟Future实现过程的例子,例子是伪代码和真实代码的混合实现,不需要太较真。
首先,假设我们定义了一个动作函数式接口Action:
public interface Action <V > V doAction () ; }
我们可以尝试实现一下Action接口:
Action<BigDecimal> action1 = () -> { sleep(x秒); return BigDecimal.valueOf(result); }; Action<Bread> action2 = () -> { sleep(x秒); return new Bread(); };
由于Action没有实现Runnable接口,上面的两个动作无法通过Executor#execute()方法提交异步任务,所以我们需要添加一个适配器ActionAdapter:
public class ActionAdapter <V > implements Runnable private Action<V> action; private ActionAdapter (Action<V> action) this .action = action; } public static <V> ActionAdapter<V> newActionAdapter (Action<V> action) { return new ActionAdapter<>(action); } @Override public void run () action.doAction(); } }
这里只做了简单粗暴的适配,虽然可以提交到线程池中执行,但是功能太过简陋。很多时候,我们还需要添加任务执行状态判断和获取结果的功能,于是新增一个接口ActionFuture:
public interface ActionFuture <V > extends Runnable V get () throws Exception ; boolean isDone () }
然后ActionAdapter实现ActionFuture接口,内部添加简单的状态控制:
public class ActionAdapter <V > implements Runnable , ActionFuture <V > private static final int NEW = 0 ; private static final int DONE = 1 ; private int state; private final Action<V> action; private Object result; private ActionAdapter (Action<V> action) this .action = action; this .state = NEW; } public static <V> ActionAdapter<V> newActionAdapter (Action<V> action) { return new ActionAdapter<>(action); } @Override public void run () try { result = action.doAction(); } catch (Throwable e) { result = e; } finally { state = DONE; } } @Override public V get () throws Exception while (state < DONE){ currentThreadWaitForResult(); } if (result instanceof Throwable){ throw new ExecutionException((Throwable) result); }else { return (V) result; } } @Override public boolean isDone () return state == DONE; } }
这里有个技巧是用Object类型的对象存放Action执行的结果或者抛出的异常实例,这样可以在ActionFuture#get()方法中进行判断和处理。最后一步,依赖Executor#execute()新增一个提交异步任务的方法:
public class ActionPool private final Executor executor; public ActionPool (Executor executor) this .executor = executor; } public <V> ActionFuture<V> submit (Action<V> action) { ActionFuture<V> actionFuture = ActionAdapter.newActionAdapter(action); executor.execute(actionFuture); return actionFuture; } public static void main (String[] args) throws Exception ActionPool pool = new ActionPool(Executors.newSingleThreadExecutor()); Action<BigDecimal> action1 = () -> { sleep(x秒); return BigDecimal.valueOf(result); }; pool.submit(action1); Action<Bread> action2 = () -> { sleep(x秒); return new Bread(); }; pool.submit(action2); } }
上面例子提到的虚拟核心组件,在JUC包中有对应的实现(当时,JUC包对逻辑和状态控制会比虚拟例子更加严谨),对应关系如下:
虚拟组件
JUC中的组件
ActionCallable
ActionFutureRunnableFuture
ActionAdapterFutureTask
ActionPoolExecutorService(ThreadPoolExecutor)
其中大部分实现逻辑都由FutureTask和ThreadPoolExecutor的抽象父类AbstractExecutorService承担,下面会重点分析这两个类核心功能的源码实现。
Tip
实际上,Future的实现使用的是Promise模式,具体可以查阅相关的资料。
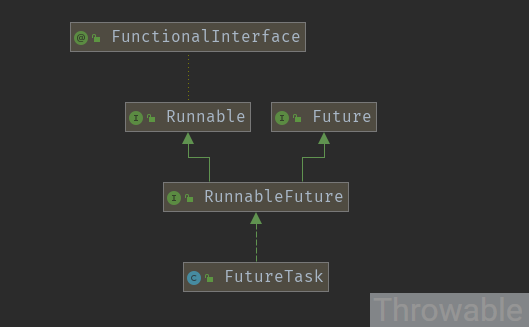
FutureTask源码实现 提供回调的Runnable类型任务实际最终都会包装为FutureTask再提交到线程池中执行,而FutureTask是Runnable、Future和Callable三者的桥梁。先看FutureTask的类继承关系:
利用接口可以多继承的特性,RunnableFuture接口继承自Runnable和Future接口:
public interface RunnableFuture <V > extends Runnable , Future <V > void run () } @FunctionalInterface public interface Runnable public abstract void run () } public interface Future <V > boolean cancel (boolean mayInterruptIfRunning) boolean isCancelled () boolean isDone () V get () throws InterruptedException, ExecutionException ; V get (long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException ;}
而FutureTask实现了RunnableFuture接口,本质就是实现Runnable和Future接口的方法。先看FutureTask的重要属性:
private volatile int state;private static final int NEW = 0 ;private static final int COMPLETING = 1 ;private static final int NORMAL = 2 ;private static final int EXCEPTIONAL = 3 ;private static final int CANCELLED = 4 ;private static final int INTERRUPTING = 5 ;private static final int INTERRUPTED = 6 ;private Callable<V> callable;private Object outcome; private volatile Thread runner;private volatile WaitNode waiters;private static final VarHandle STATE;private static final VarHandle RUNNER;private static final VarHandle WAITERS;static { try { MethodHandles.Lookup l = MethodHandles.lookup(); STATE = l.findVarHandle(FutureTask.class, "state" , int .class); RUNNER = l.findVarHandle(FutureTask.class, "runner" , Thread.class); WAITERS = l.findVarHandle(FutureTask.class, "waiters" , WaitNode.class); } catch (ReflectiveOperationException e) { throw new ExceptionInInitializerError(e); } Class<?> ensureLoaded = LockSupport.class; }
上面的主要属性中,有两点比较复杂,但却是最重要的:
FutureTask生命周期的状态管理或者跃迁。等待(获取结果)线程集合WaitNode基于Treiber Stack实现,需要彻底弄清楚Treiber Stack的工作原理。
FutureTask的状态管理 FutureTask的内建状态包括了七种,也就是属性state有七种可选状态值,总结成表格如下:
状态
状态值
描述
NEW0
初始化状态,FutureTask实例创建时候在构造函数中标记为此状态
COMPLETING1
完成中状态,这个是中间状态,执行完成后设置outcome之前标记为此状态
NORMAL2
正常执行完成,通过调用get()方法能够获取正确的计算结果
EXCEPTIONAL3
异常执行完成,通过调用get()方法会抛出包装后的ExecutionException异常
CANCELLED4
取消状态
INTERRUPTING5
中断中状态,执行线程实例Thread#interrupt()之前会标记为此状态
INTERRUPTED6
中断完成状态
这些状态之间的跃迁流程图如下:
每一种状态跃迁都是由于调用或者触发了某个方法,下文的一个小节会分析这些方法的实现。
等待线程集合数据结构Treiber Stack的原理 Treiber Stack,中文翻译是驱动栈 ,听起来比较怪。实际上,Treiber Stack算法是R. Kent Treiber在其1986年的论文Systems Programming: Coping with Parallelism中首次提出,这种算法提供了一种可扩展的无锁栈 ,基于细粒度的并发原语CAS(Compare And Swap)实现。笔者并没有花时间去研读Treiber的论文,因为在Doug Lea大神参与编写的《Java Concurrency in Practice(Java并发编程实战)》中的第15.4.1小节中有简单分析非阻塞算法中的非阻塞栈。
在实现相同功能的前提下,非阻塞算法通常比基于锁的算法更加复杂。创建非阻塞算法的关键在于,找出如何将原子修改的范围缩小到单个变量上,同时还要维护数据的一致性。下面的ConcurrentStack是基于Java语言实现的Treiber算法:
public class ConcurrentStack <E > private AtomicReference<Node<E>> top = new AtomicReference<>(); public void push (E item) Node<E> newHead = new Node<>(item); Node<E> oldHead; do { oldHead = top.get(); newHead.next = oldHead; } while (!top.compareAndSet(oldHead, newHead)); } public E pop () Node<E> oldHead; Node<E> newHead; do { oldHead = top.get(); if (null == oldHead) { return null ; } newHead = oldHead.next; } while (!top.compareAndSet(oldHead, newHead)); return oldHead.item; } private static class Node <E > final E item; Node<E> next; Node(E item) { this .item = item; } } }
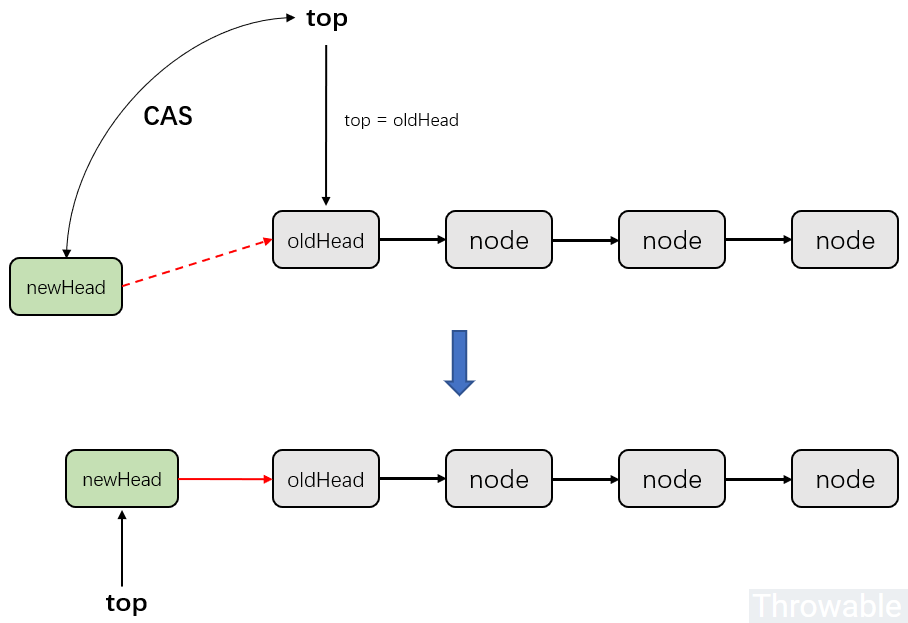
ConcurrentStack是一个栈,它是由Node元素构成的一个链表,其中栈顶作为根节点,并且每个元素都包含了一个值以及指向下一个元素的链接。push()方法创建一个新的节点,该节点的next域指向了当前的栈顶,然后通过CAS把这个新节点放入栈顶。如果在开始插入节点时,位于栈顶的节点没有发生变化,那么CAS就会成功,如果栈顶节点发生变化(例如由于其他线程在当前线程开始之前插入或者移除了元素),那么CAS就会失败,而push()方法会根据栈的当前状态来更新节点(其实就是while循环会进入下一轮),并且再次尝试。无论哪种情况,在CAS执行完成之后,栈仍然回处于一致的状态。这里通过一个图来模拟一下push()方法的流程:
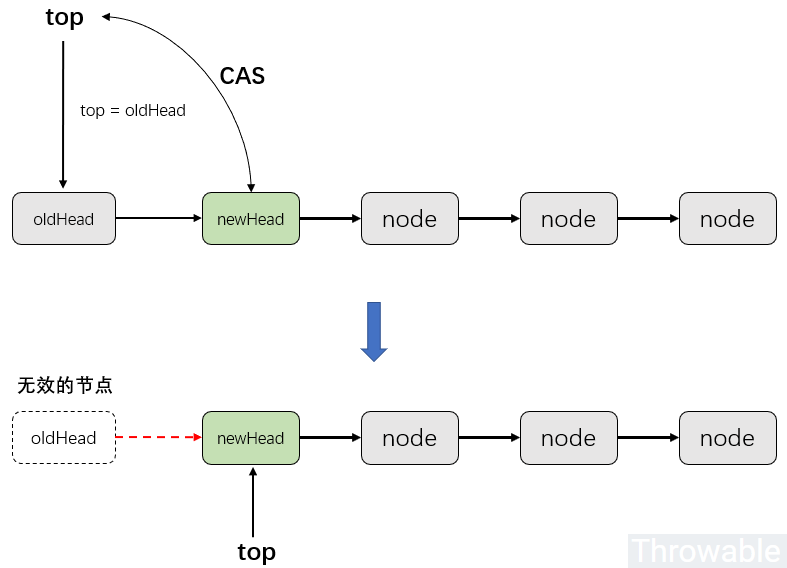
而pop()方法可以简单理解为push()方法的逆向操作,具体流程是:
创建一个引用newHead指向当前top的下一个节点,也就是top.next,top所在引用称为oldHead。
通过CAS更新top的值,伪代码是CAS(expect=oldHead,update=newHead),如果更新成功,那么top就指向top.next,也就是newHead。
Warning
这里可以看出Treiber Stack算法有个比较大的问题是有可能产生无效的节点,所以FutureTask也存在可能产生无效的等待节点的问题。
FutureTask方法源码分析 先看FutureTask提供的非阻塞栈节点的实现:
static final class WaitNode volatile Thread thread; volatile WaitNode next; WaitNode() { thread = Thread.currentThread(); } }
和我们上面分析Treiber Stack时候使用的单链表如出一辙。接着看FutureTask的构造函数:
public FutureTask (Callable<V> callable) if (callable == null ) throw new NullPointerException(); this .callable = callable; this .state = NEW; } public FutureTask (Runnable runnable, V result) this .callable = Executors.callable(runnable, result); this .state = NEW; } public static <T> Callable<T> callable (Runnable task, T result) { if (task == null ) throw new NullPointerException(); return new RunnableAdapter<T>(task, result); } private static final class RunnableAdapter <T > implements Callable <T > private final Runnable task; private final T result; RunnableAdapter(Runnable task, T result) { this .task = task; this .result = result; } public T call () task.run(); return result; } public String toString () return super .toString() + "[Wrapped task = " + task + "]" ; } }
主要是针对两种不同场景的任务类型进行适配,构造函数中直接设置状态state = NEW(0)。因为FutureTask是最终的任务包装类,它的核心功能都在其实现的Runnable#run()方法中,这里重点分析一下run()方法:
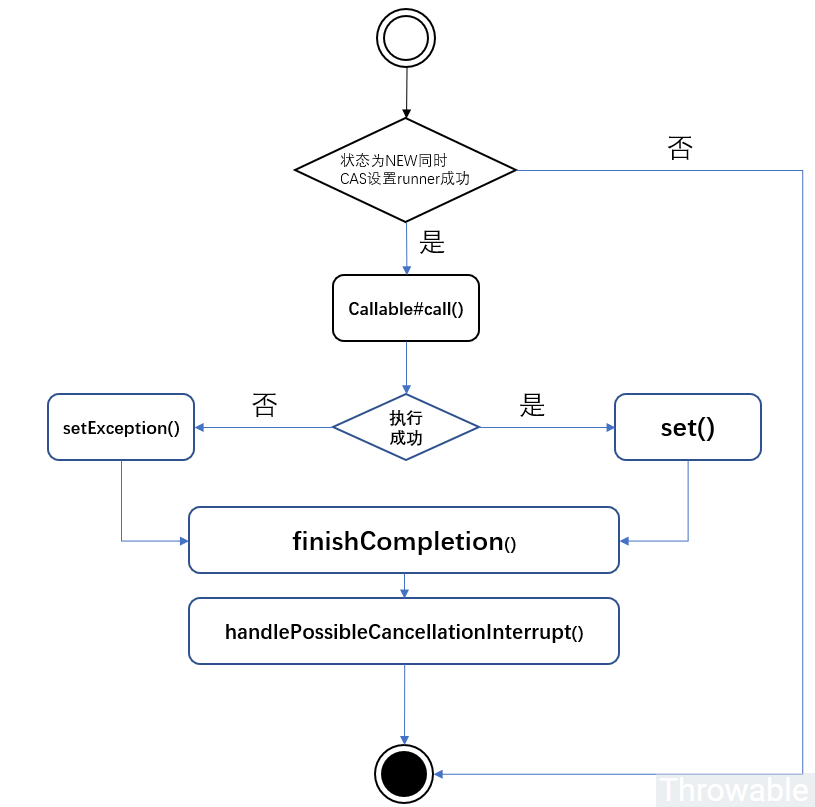
public void run () if (state != NEW || !RUNNER.compareAndSet(this , null , Thread.currentThread())) return ; try { Callable<V> c = callable; if (c != null && state == NEW) { V result; boolean ran; try { result = c.call(); ran = true ; } catch (Throwable ex) { result = null ; ran = false ; setException(ex); } if (ran) set(result); } } finally { runner = null ; int s = state; if (s >= INTERRUPTING) handlePossibleCancellationInterrupt(s); } } protected void setException (Throwable t) if (STATE.compareAndSet(this , NEW, COMPLETING)) { outcome = t; STATE.setRelease(this , EXCEPTIONAL); finishCompletion(); } } private void finishCompletion () for (WaitNode q; (q = waiters) != null ;) { if (WAITERS.weakCompareAndSet(this , q, null )) { for (;;) { Thread t = q.thread; if (t != null ) { q.thread = null ; LockSupport.unpark(t); } WaitNode next = q.next; if (next == null ) break ; q.next = null ; q = next; } break ; } } done(); callable = null ; } protected void set (V v) if (STATE.compareAndSet(this , NEW, COMPLETING)) { outcome = v; STATE.setRelease(this , NORMAL); finishCompletion(); } } private void handlePossibleCancellationInterrupt (int s) if (s == INTERRUPTING) while (state == INTERRUPTING) Thread.yield(); } protected void done () }
run()方法的执行流程比较直观,这里提供一个简单的流程图:
FutureTask还提供了一个能够重置状态(准确来说是保持状态)的runAndReset()方法,这个方法专门提供给ScheduledThreadPoolExecutor使用:
protected boolean runAndReset () if (state != NEW || !RUNNER.compareAndSet(this , null , Thread.currentThread())) return false ; boolean ran = false ; int s = state; try { Callable<V> c = callable; if (c != null && s == NEW) { try { c.call(); ran = true ; } catch (Throwable ex) { setException(ex); } } } finally { runner = null ; s = state; if (s >= INTERRUPTING) handlePossibleCancellationInterrupt(s); } return ran && s == NEW; }
runAndReset()方法保证了在任务正常执行完成之后返回true,此时FutureTask的状态state保持为NEW,由于没有调用set()方法,也就是没有调用finishCompletion()方法,它内部持有的Callable任务引用不会置为null,等待获取结果的线程集合也不会解除阻塞。这种设计方案专门针对可以周期性重复执行的任务。异常执行情况和取消的情况导致的最终结果和run()方法是一致的。接下来分析一下获取执行结果的get()方法:
public V get () throws InterruptedException, ExecutionException int s = state; if (s <= COMPLETING) s = awaitDone(false , 0L ); return report(s); } public V get (long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { if (unit == null ) throw new NullPointerException(); int s = state; if (s <= COMPLETING && (s = awaitDone(true , unit.toNanos(timeout))) <= COMPLETING) throw new TimeoutException(); return report(s); } private int awaitDone (boolean timed, long nanos) throws InterruptedException long startTime = 0L ; WaitNode q = null ; boolean queued = false ; for (;;) { int s = state; if (s > COMPLETING) { if (q != null ) q.thread = null ; return s; } else if (s == COMPLETING) Thread.yield(); else if (Thread.interrupted()) { removeWaiter(q); throw new InterruptedException(); } else if (q == null ) { if (timed && nanos <= 0L ) return s; q = new WaitNode(); } else if (!queued) queued = WAITERS.weakCompareAndSet(this , q.next = waiters, q); else if (timed) { final long parkNanos; if (startTime == 0L ) { startTime = System.nanoTime(); if (startTime == 0L ) startTime = 1L ; parkNanos = nanos; } else { long elapsed = System.nanoTime() - startTime; if (elapsed >= nanos) { removeWaiter(q); return state; } parkNanos = nanos - elapsed; } if (state < COMPLETING) LockSupport.parkNanos(this , parkNanos); } else LockSupport.park(this ); } } private void removeWaiter (WaitNode node) if (node != null ) { node.thread = null ; retry: for (;;) { for (WaitNode pred = null , q = waiters, s; q != null ; q = s) { s = q.next; if (q.thread != null ) pred = q; else if (pred != null ) { pred.next = s; if (pred.thread == null ) continue retry; } else if (!WAITERS.compareAndSet(this , q, s)) continue retry; } break ; } } } private V report (int s) throws ExecutionException Object x = outcome; if (s == NORMAL) return (V)x; if (s >= CANCELLED) throw new CancellationException(); throw new ExecutionException((Throwable)x); }
上面的方法中,removeWaiter()方法相对复杂,它涉及到单链表移除中间节点、考虑多种竞态情况进行重试等设计,需要花大量心思去理解。接着看cancel()方法:
public boolean cancel (boolean mayInterruptIfRunning) if (!(state == NEW && STATE.compareAndSet(this , NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED))) return false ; try { if (mayInterruptIfRunning) { try { Thread t = runner; if (t != null ) t.interrupt(); } finally { STATE.setRelease(this , INTERRUPTED); } } } finally { finishCompletion(); } return true ; }
cancel()方法只能够中断状态为NEW(0)的线程,并且由于线程只在某些特殊情况下(例如阻塞在同步代码块或者同步方法中阻塞在Object#wait()方法、主动判断线程的中断状态等等)才能响应中断,所以需要思考这个方法是否可以达到预想的目的。最后看剩下的状态判断方法:
public boolean isCancelled () return state >= CANCELLED; } public boolean isDone () return state != NEW; }
AbstractExecutorService源码实现 AbstractExecutorService虽然只是ThreadPoolExecutor的抽象父类,但是它已经实现了ExecutorService接口中除了shutdown()、shutdownNow()、isShutdown()、isTerminated()和awaitTermination()五个方法之外的其他所有方法(这五个方法在ThreadPoolExecutor实现,因为它们是和线程池的状态相关的)。它的源码体积比较小,下面全量贴出分析:
public abstract class AbstractExecutorService implements ExecutorService protected <T> RunnableFuture<T> newTaskFor (Runnable runnable, T value) { return new FutureTask<T>(runnable, value); } protected <T> RunnableFuture<T> newTaskFor (Callable<T> callable) { return new FutureTask<T>(callable); } public Future<?> submit(Runnable task) { if (task == null ) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null ); execute(ftask); return ftask; } public <T> Future<T> submit (Runnable task, T result) { if (task == null ) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; } public <T> Future<T> submit (Callable<T> task) { if (task == null ) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; } private <T> T doInvokeAny (Collection<? extends Callable<T>> tasks, boolean timed, long nanos) throws InterruptedException, ExecutionException, TimeoutException { if (tasks == null ) throw new NullPointerException(); int ntasks = tasks.size(); if (ntasks == 0 ) throw new IllegalArgumentException(); ArrayList<Future<T>> futures = new ArrayList<>(ntasks); ExecutorCompletionService<T> ecs = new ExecutorCompletionService<T>(this ); try { ExecutionException ee = null ; final long deadline = timed ? System.nanoTime() + nanos : 0L ; Iterator<? extends Callable<T>> it = tasks.iterator(); futures.add(ecs.submit(it.next())); --ntasks; int active = 1 ; for (;;) { Future<T> f = ecs.poll(); if (f == null ) { if (ntasks > 0 ) { --ntasks; futures.add(ecs.submit(it.next())); ++active; } else if (active == 0 ) break ; else if (timed) { f = ecs.poll(nanos, NANOSECONDS); if (f == null ) throw new TimeoutException(); nanos = deadline - System.nanoTime(); } else f = ecs.take(); } if (f != null ) { --active; try { return f.get(); } catch (ExecutionException eex) { ee = eex; } catch (RuntimeException rex) { ee = new ExecutionException(rex); } } } if (ee == null ) ee = new ExecutionException(); throw ee; } finally { cancelAll(futures); } } public <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException { try { return doInvokeAny(tasks, false , 0 ); } catch (TimeoutException cannotHappen) { assert false ; return null ; } } public <T> T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { return doInvokeAny(tasks, true , unit.toNanos(timeout)); } public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException { if (tasks == null ) throw new NullPointerException(); ArrayList<Future<T>> futures = new ArrayList<>(tasks.size()); try { for (Callable<T> t : tasks) { RunnableFuture<T> f = newTaskFor(t); futures.add(f); execute(f); } for (int i = 0 , size = futures.size(); i < size; i++) { Future<T> f = futures.get(i); if (!f.isDone()) { try { f.get(); } catch (CancellationException | ExecutionException ignore) {} } } return futures; } catch (Throwable t) { cancelAll(futures); throw t; } } public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException { if (tasks == null ) throw new NullPointerException(); final long nanos = unit.toNanos(timeout); final long deadline = System.nanoTime() + nanos; ArrayList<Future<T>> futures = new ArrayList<>(tasks.size()); int j = 0 ; timedOut: try { for (Callable<T> t : tasks) futures.add(newTaskFor(t)); final int size = futures.size(); for (int i = 0 ; i < size; i++) { if (((i == 0 ) ? nanos : deadline - System.nanoTime()) <= 0L ) break timedOut; execute((Runnable)futures.get(i)); } for (; j < size; j++) { Future<T> f = futures.get(j); if (!f.isDone()) { try { f.get(deadline - System.nanoTime(), NANOSECONDS); } catch (CancellationException | ExecutionException ignore) {} catch (TimeoutException timedOut) { break timedOut; } } } return futures; } catch (Throwable t) { cancelAll(futures); throw t; } cancelAll(futures, j); return futures; } private static <T> void cancelAll (ArrayList<Future<T>> futures) cancelAll(futures, 0 ); } private static <T> void cancelAll (ArrayList<Future<T>> futures, int j) for (int size = futures.size(); j < size; j++) futures.get(j).cancel(true ); } }
整个类的源码并不复杂,注意到Callable和Runnable的任务最重都会包装为适配器FutureTask的实例,然后通过execute()方法提交包装好的FutureTask任务实例,返回值是Future或者Future的集合时候,实际上是RunnableFuture或者RunnableFuture的集合,只因为RunnableFuture是Future的子接口,这种设计遵循了设计模式原则里面的依赖倒置原则 。这里小结一下分析过的几个方法的特征:
方法
特征
submit(Runnable task)异步执行,执行结果无感知,通过get()方法虽然返回null但是可以确定执行完毕的时刻
submit(Runnable task, T result)异步执行,预先传入执行结果,最终通过get()方法返回的就是初始传入的结果
submit(Callable<T> task)异步执行,最终通过get()方法返回的是Callable#call()的结果
invokeAny(Collection<? extends Callable<T>> tasks)异步执行任务列表中的任意一个任务(实际上有可能会执行多个任务,确保最先完成的任务对应的结果返回),永久阻塞同步返回结果
invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)功能同上,获取结果的时候是超时阻塞获取
invokeAll(Collection<? extends Callable<T>> tasks)异步执行任务列表中的所有任务,必须等待所有Future#get()永久阻塞方法都返回了结果才返回Future列表
invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)异步执行任务列表中的所有任务,只要其中一个任务Future#get()超时阻塞方法超时就会取消该任务索引之后的所有任务并且返回Future列表
小结 ExecutorService提供了一系列便捷的异步任务提交方法,它使用到多种技术:
相对底层的CAS原语。
基于CAS实现的无锁并发栈。
依赖于线程池实现的execute()方法进行异步任务提交。
使用适配器模式设计FutureTask适配Futrue、Runnable和Callable,提供了状态的生命周期管理。
下一篇文章将会分析一下调度线程池ScheduledThreadPoolExecutor的底层实现和源码。
(本文完 c-7-d e-a-20190727)