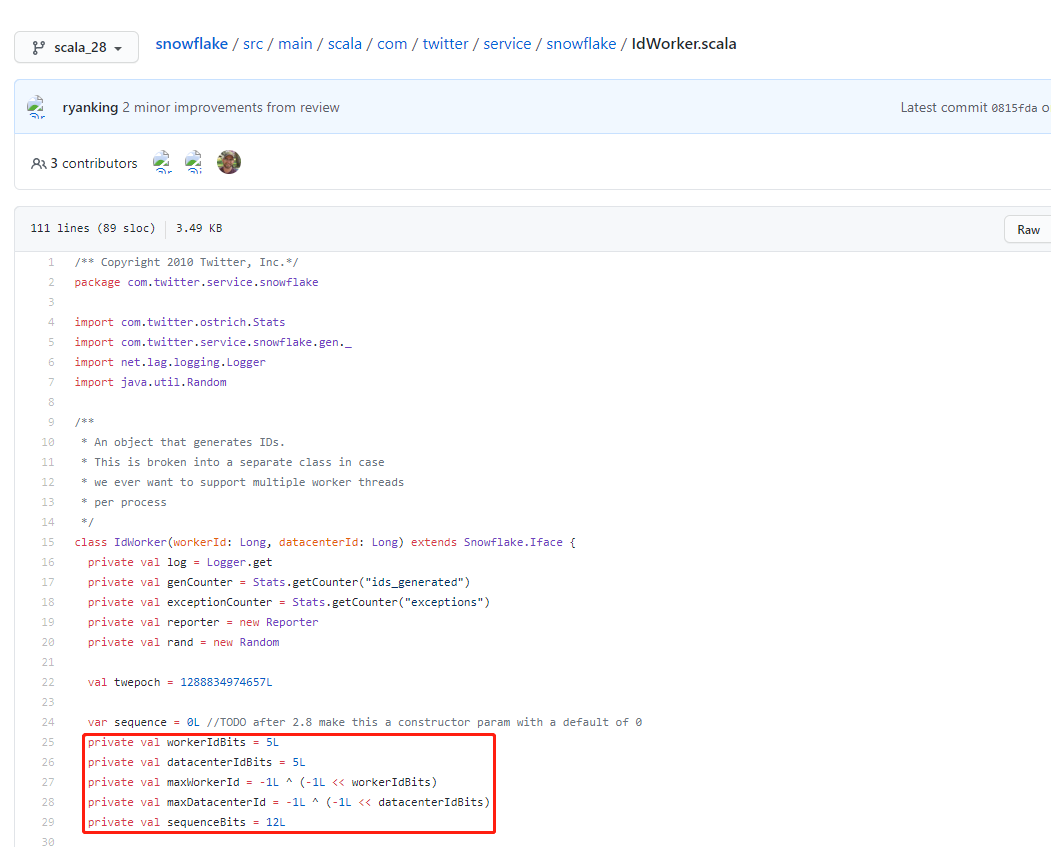
// 下面的代码块为参数校验和初始化日志打印,这里不做分析 if (workerId > maxWorkerId || workerId < 0) { exceptionCounter.incr(1) thrownew IllegalArgumentException("worker Id can't be greater than %d or less than 0".format(maxWorkerId)) }
if (datacenterId > maxDatacenterId || datacenterId < 0) { exceptionCounter.incr(1) thrownew IllegalArgumentException("datacenter Id can't be greater than %d or less than 0".format(maxDatacenterId)) }
log.info("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d", timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId)
接着看算法的核心代码逻辑:
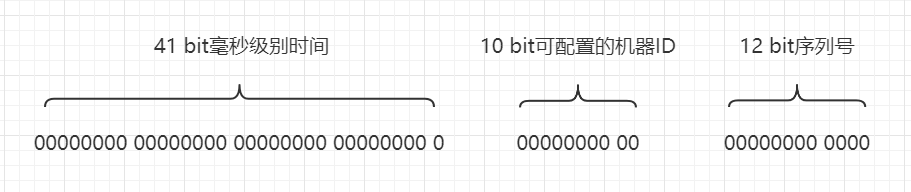
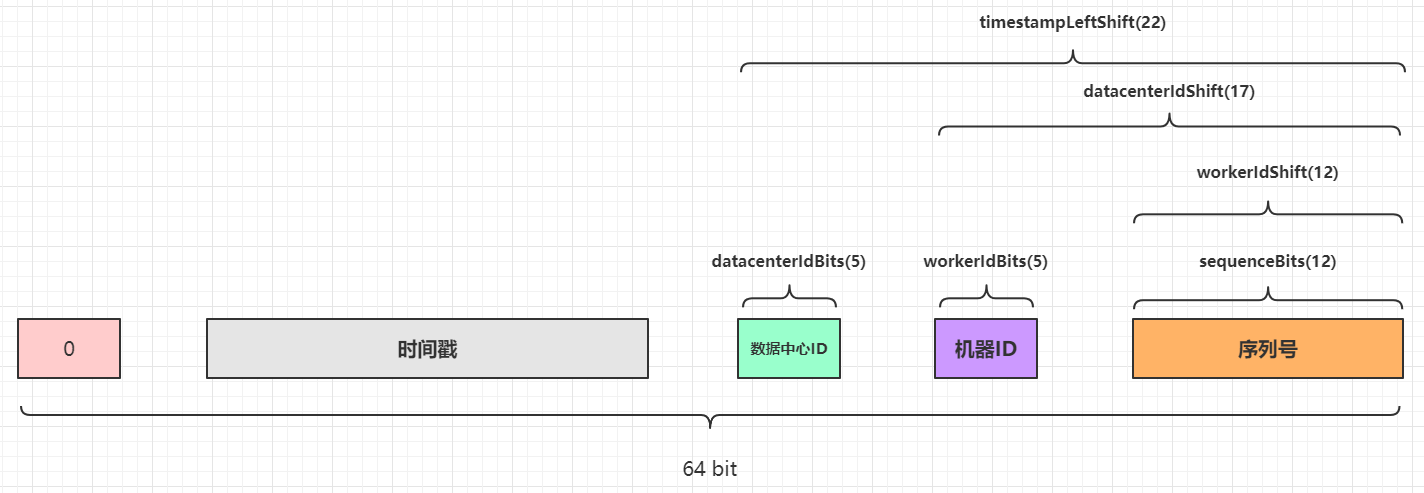
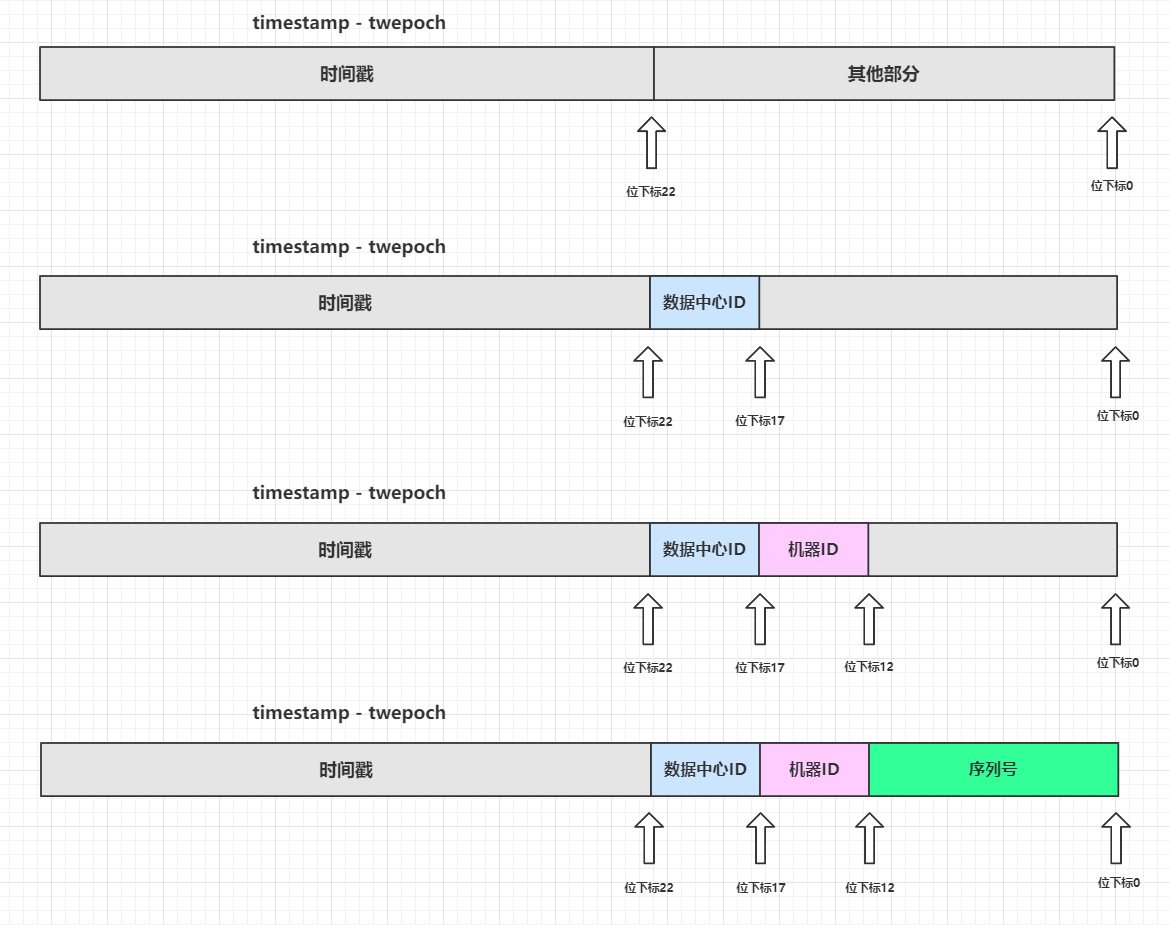
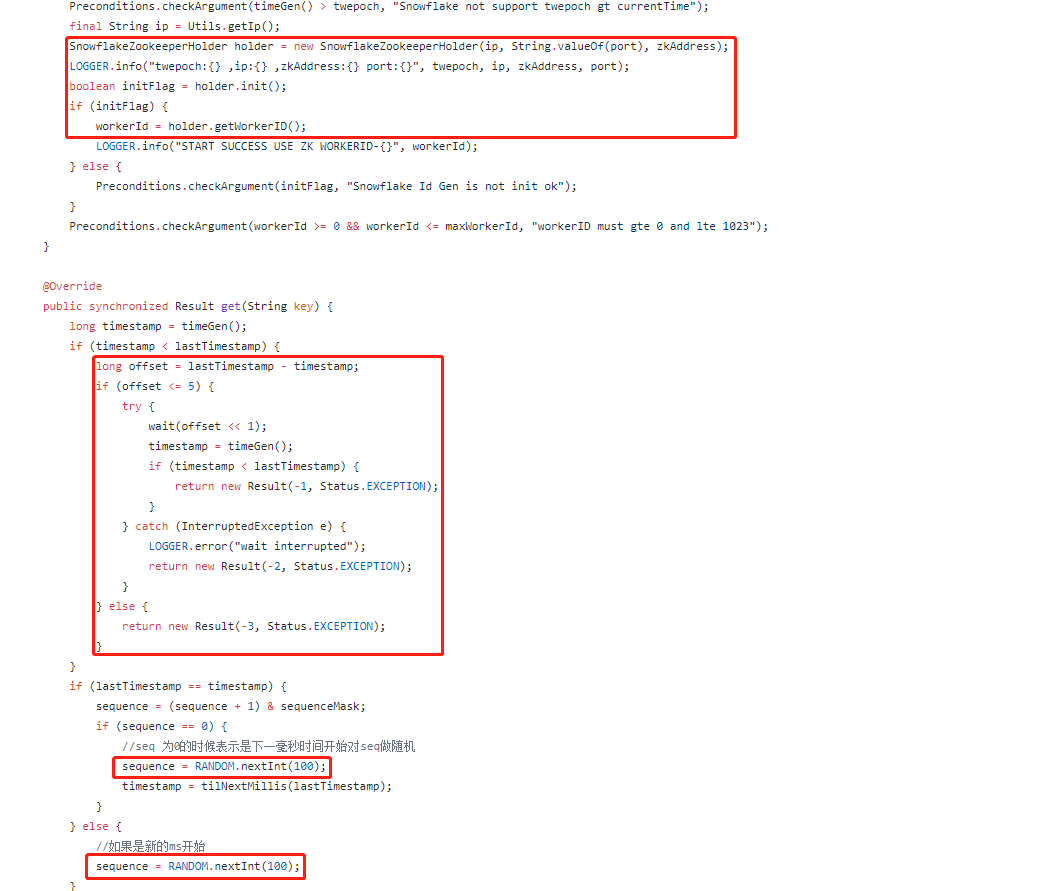
// 同步方法,其实就是protected synchronized long nextId(){ ...... } protected[snowflake] def nextId(): Long = synchronized { // 获取系统时间戳(毫秒) var timestamp = timeGen() // 高并发场景,同一毫秒内生成多个ID if (lastTimestamp == timestamp) { // 确保sequence + 1之后不会溢出,最大值为4095,其实也就是保证1毫秒内最多生成4096个ID值 sequence = (sequence + 1) & sequenceMask // 如果sequence溢出则变为0,说明1毫秒内并发生成的ID数量超过了4096个,这个时候同1毫秒的第4097个生成的ID必须等待下一毫秒 if (sequence == 0) { // 死循环等待下一个毫秒值,直到比lastTimestamp大 timestamp = tilNextMillis(lastTimestamp) } } else { // 低并发场景,不同毫秒中生成ID // 不同毫秒的情况下,由于外层方法保证了timestamp大于或者小于lastTimestamp,而小于的情况是发生了时钟回拨,下面会抛出异常,所以不用考虑 // 也就是只需要考虑一种情况:timestamp > lastTimestamp,也就是当前生成的ID所在的毫秒数比上一个ID大 // 所以如果时间戳部分增大,可以确定整数值一定变大,所以序列号其实可以不用计算,这里直接赋值为0 sequence = 0 } // 获取到的时间戳比上一个保存的时间戳小,说明时钟回拨,这种情况下直接抛出异常,拒绝生成ID // 个人认为,这个方法应该可以提前到var timestamp = timeGen()这段代码之后 if (timestamp < lastTimestamp) { exceptionCounter.incr(1) log.error("clock is moving backwards. Rejecting requests until %d.", lastTimestamp); thrownew InvalidSystemClock("Clock moved backwards. Refusing to generate id for %d milliseconds".format(lastTimestamp - timestamp)); } // lastTimestamp保存当前时间戳,作为方法下次被调用的上一个时间戳的快照 lastTimestamp = timestamp // 度量统计,生成的ID计数器加1 genCounter.incr() // X = (系统时间戳 - 自定义的纪元值) 然后左移22位 // Y = (数据中心ID左移17位) // Z = (机器ID左移12位) // 最后ID = X | Y | Z | 计算出来的序列号sequence ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence }
// 辅助方法:获取系统当前的时间戳(毫秒) protected def timeGen(): Long = System.currentTimeMillis()
// 辅助方法:获取系统当前的时间戳(毫秒),用死循环保证比传入的lastTimestamp大,也就是获取下一个比lastTimestamp大的毫秒数 protected def tilNextMillis(lastTimestamp: Long): Long = { var timestamp = timeGen() while (timestamp <= lastTimestamp) { timestamp = timeGen() } timestamp }
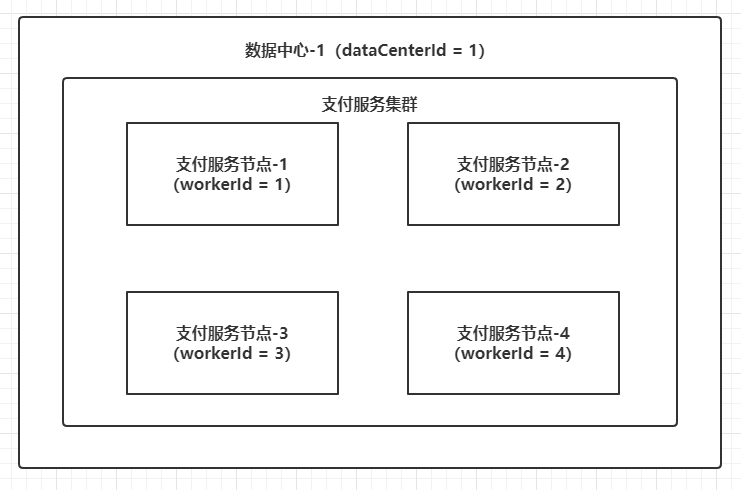
Woker ID和Data Center ID的配置是极其重要的,对于同一个服务(例如支付服务)集群的多个节点,必须配置不同的机器ID和数据中心ID或者同样的数据中心ID和不同的机器ID(简单说就是确保Woker ID和Data Center ID的组合全局唯一),否则在高并发的场景下,在系统时钟一致的情况下,很容易在多个节点产生相同的ID值,所以一般的部署架构如下:
管理这两个ID的方式有很多种,或者像Leaf这样的开源框架引入分布式缓存进行管理,再如笔者所在的创业小团队生产服务比较少,直接把Woker ID和Data Center ID硬编码在服务启动脚本中,然后把所有服务使用的Woker ID和Data Center ID统一登记在团队内部知识库中。
publicSimpleSnowflake(long workerId, long dataCenterId, long epoch){ this.workerId = workerId; this.dataCenterId = dataCenterId; this.epoch = epoch; checkArgs(); }
privatevoidcheckArgs(){ if (!(MIN_WORKER_ID <= workerId && workerId <= MAX_WORKER_ID)) { thrownew IllegalArgumentException("Worker id must be in [0,31]"); } if (!(MIN_DC_ID <= dataCenterId && dataCenterId <= MAX_DC_ID)) { thrownew IllegalArgumentException("Data center id must be in [0,31]"); } }
通过字符串拼接的写法虽然运行效率低,但是可读性会比较高,工程化处理后的代码可以在实例化时候直接指定Worker ID和Data Center ID等值,并且这个简易的Snowflake实现没有第三方库依赖,拷贝下来可以直接运行。上面的方法使用字符串拼接看起来比较低端,其实最后那部分的按位或,可以完全转化为加法: