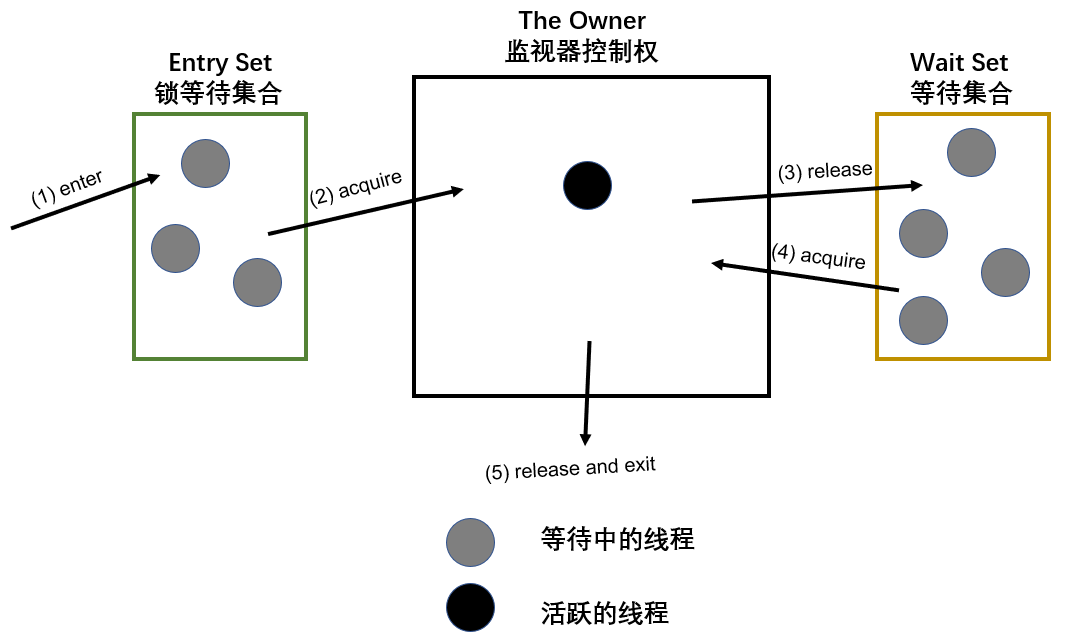
CountDownLatch doneSignal = new CountDownLatch(N); Executor e = ... for (int i = 0; i < N; ++i) { e.execute(new WorkerRunnable(doneSignal, i)); } doneSignal.await();
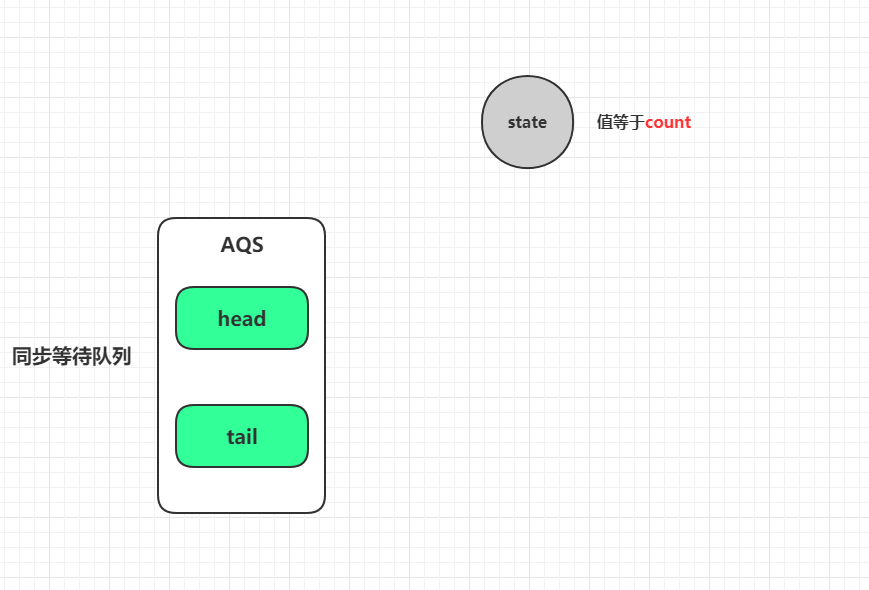
↓↓↓↓↓↓↓↓↓↓↓↓ // 私有静态内部类Sync中 privatestaticfinalclassSyncextendsAbstractQueuedSynchronizer{ // 共享模式下释放资源,这里也无视共享模式下需要释放的资源数,每次让状态值通过CAS减少1,当减少到0的时候,返回true protectedbooleantryReleaseShared(int releases){ // 减少计数值state,直到变为0,则进行释放 for (;;) { int c = getState(); // 如果已经为0,直接返回false,不能再递减到小于0,返回false也意味着不会进入AQS的doReleaseShared()逻辑 if (c == 0) returnfalse; int nextc = c - 1; // CAS原子更新state = state - 1 if (compareAndSetState(c, nextc)) // 如果此次递减为0则返回true return nextc == 0; } }
// ...... }
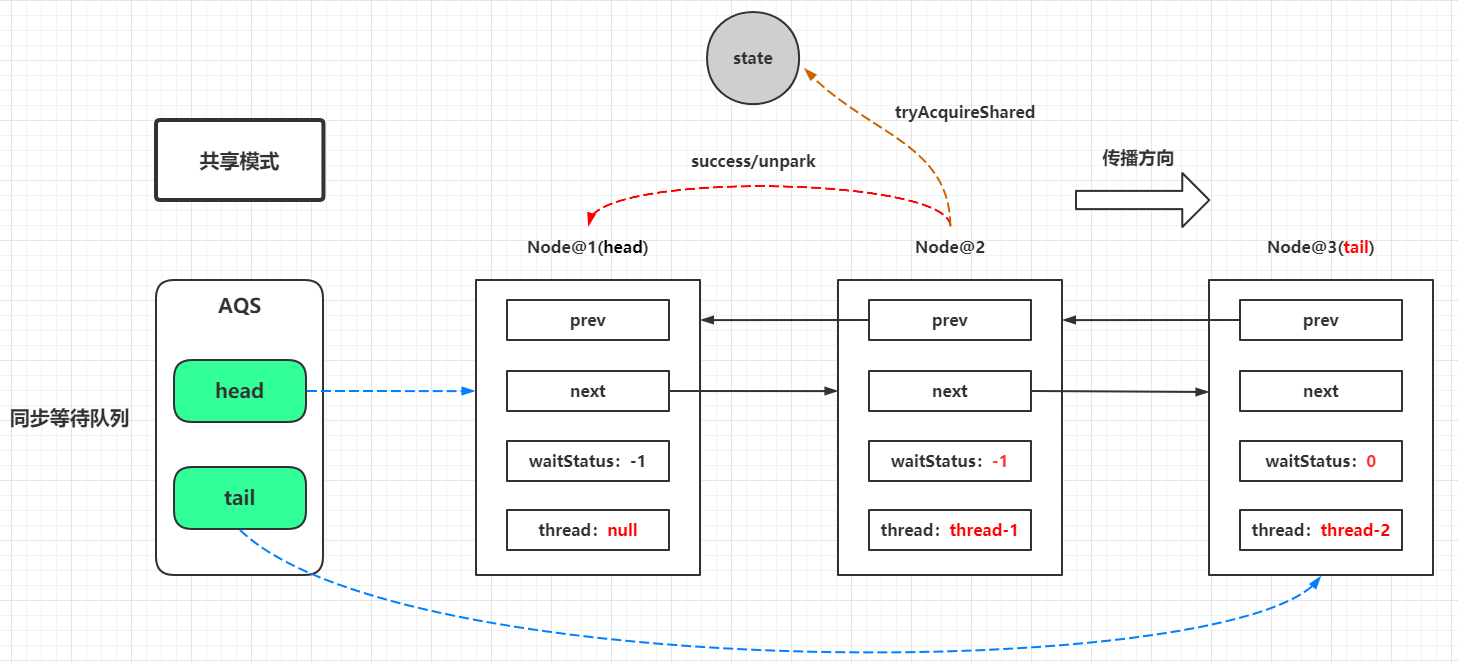
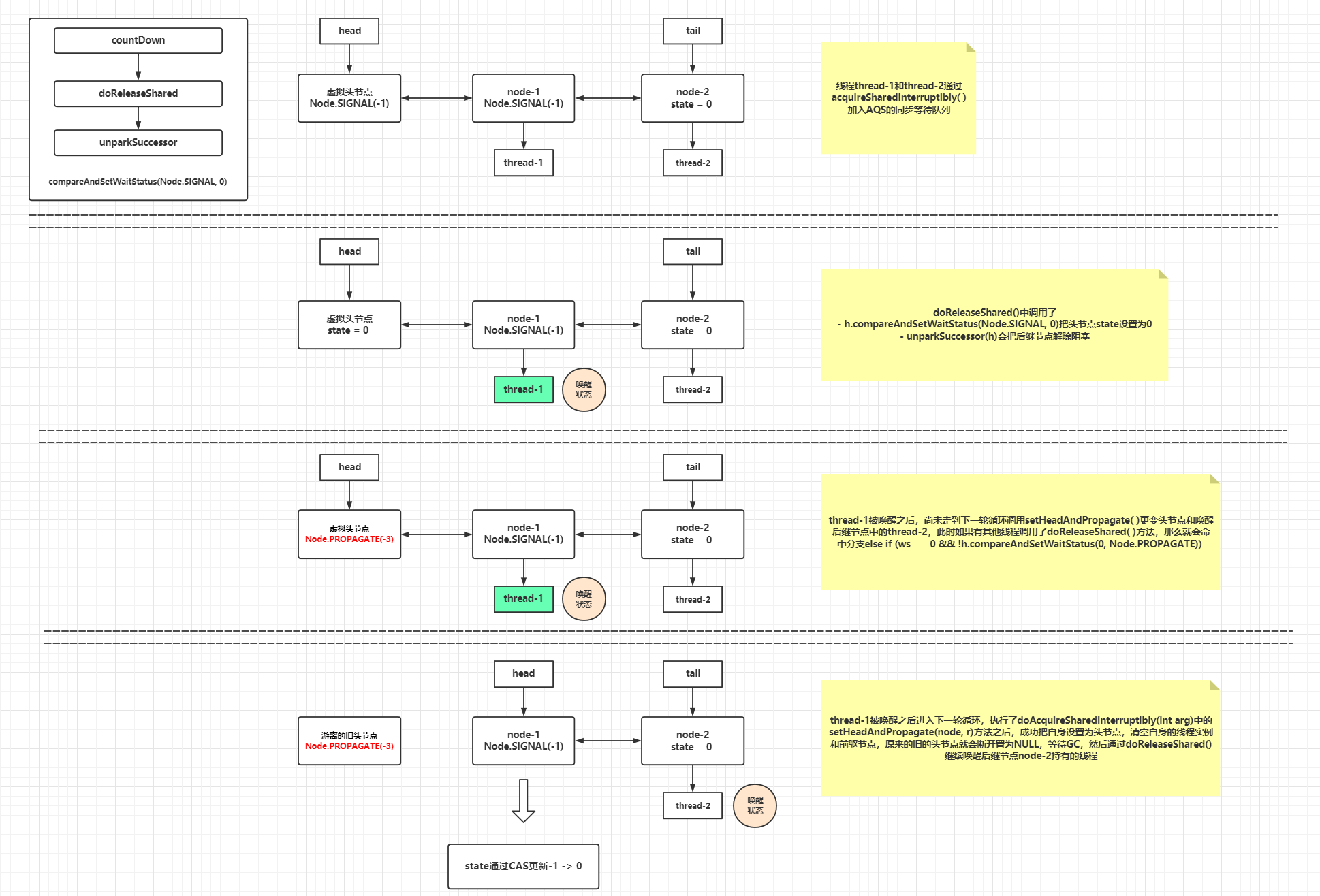
↓↓↓↓↓↓↓↓↓↓↓↓ // AbstractQueuedSynchronizer中 publicabstractclassAbstractQueuedSynchronizerextendsAbstractOwnableSynchronizerimplementsjava.io.Serializable{ // ...... // 共享模式下,释放arg个资源 publicfinalbooleanreleaseShared(int arg){ // 从上面的分析来看,这里只有一种可能返回true并且进入doReleaseShared()方法,就是state由1递减为0的时候 if (tryReleaseShared(arg)) { doReleaseShared(); returntrue; } returnfalse; } // 共享模式下的释放操作 privatevoiddoReleaseShared(){ // 死循环是避免因为新节点入队产生影响,CAS做状态设置被放在死循环中失败了会在下一轮循环中重试 for (;;) { Node h = head; // 头不等于尾,也就是AQS同步等待队列不为空 // h == NULL,说明AQS同步等待队列刚进行了初始化,并未有持有线程实例的节点 if (h != null && h != tail) { int ws = h.waitStatus; // 头节点为Node.SIGNAL(-1),也就是后继节点需要唤醒,CAS设置头节点状态-1 -> 0,并且唤醒头节点的后继节点(也就是紧挨着头节点后的第一个节点) if (ws == Node.SIGNAL) { // 这个if分支是对于Node.SIGNAL状态的头节点,这种情况下,说明 // 这里使用CAS的原因是setHeadAndPropagate()方法和releaseXX()方法都会调用此doReleaseShared()方法,CAS也是并发控制的一种手段 // 如果CAS失败,很大可能是头节点发生了变更,需要进入下一轮循环更变头节点的引用再进行判断 // 该状态一定是由后继节点为当前节点设置的,具体见shouldParkAfterFailedAcquire()方法 if (!h.compareAndSetWaitStatus(Node.SIGNAL, 0)) continue; // loop to recheck cases // 唤醒后继节点,如果有后继节点被唤醒,则后继节点会调用setHeadAndPropagate()方法,更变头节点和转播唤醒状态 unparkSuccessor(h); } // 头节点状态为0,说明头节点的后继节点未设置前驱节点的waitStatus为SIGNAL,代表无需唤醒 // CAS更新它的状态0 -> Node.PROPAGATE(-3),这个标识目的是为了把节点状态设置为跟Node.SIGNAL(-1)一样的负数值, // 便于某个后继节点解除阻塞后,在一轮doAcquireSharedInterruptibly()循环中调用shouldParkAfterFailedAcquire()方法返回false,实现"链式唤醒" elseif (ws == 0 && !h.compareAndSetWaitStatus(0, Node.PROPAGATE)) continue; // loop on failed CAS } // 如果头节点未发生变化,则代表当前没有其他线程获取到资源,晋升为头节点,直接退出循环 // 如果头节点已经发生变化,代表已经有线程(后继节点)获取到资源, if (h == head) // loop if head changed break; } }
// 解除传入节点的第一个后继节点的阻塞状态,当前处理节点的等待状态会被CAS更新为0 privatevoidunparkSuccessor(Node node){ // 当前处理的节点状态小于0则直接CAS更新为0 int ws = node.waitStatus; if (ws < 0) node.compareAndSetWaitStatus(ws, 0); // 如果节点的第一个后继节点为null或者等待状态大于0(取消),则从等待队列的尾节点向前遍历, // 找到最后一个(这里指的是队列尾部->队列头部搜索路径的最后一个满足的节点,一般是传入的node节点的next节点)不为null,并且等待状态小于等于0的节点 Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; for (Node p = tail; p != node && p != null; p = p.prev) if (p.waitStatus <= 0) s = p; } // 解除传入节点的后继节点的阻塞状态,唤醒后继节点所存放的线程 if (s != null) LockSupport.unpark(s.thread); } // ...... }
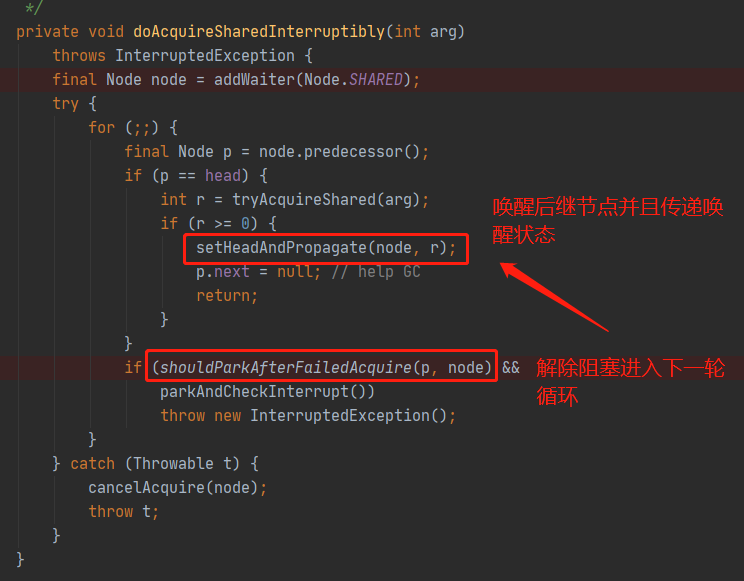
privatevoidsetHeadAndPropagate(Node node, int propagate){ // 这里的临时变量h存放了旧的头节点引用 Node h = head; // Record old head for check below // 这里的输入参数node基本上就是原来旧头节点的后继节点,而propagate的值来源于tryAcquireShared(),由图中可知propagate >= 0 恒成立 setHead(node); /* * Try to signal next queued node if: * Propagation was indicated by caller, * or was recorded (as h.waitStatus either before * or after setHead) by a previous operation * (note: this uses sign-check of waitStatus because * PROPAGATE status may transition to SIGNAL.) * and * The next node is waiting in shared mode, * or we don't know, because it appears null * * The conservatism in both of these checks may cause * unnecessary wake-ups, but only when there are multiple * racing acquires/releases, so most need signals now or soon * anyway. */ // 这里是一个很复杂的IF条件,下文一个一个条件看 if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0) { Node s = node.next; if (s == null || s.isShared()) doReleaseShared(); } }
// 判断当获取资源失败的时候是否应该阻塞当前处理的节点中的线程实例 // node为当前处理的节点或者新入队的节点 // pred则为node的前驱节点 privatestaticbooleanshouldParkAfterFailedAcquire(Node pred, Node node){ // 前驱节点的状态值 int ws = pred.waitStatus; // 前驱节点处于Node.SIGNAL(-1)状态,说明当前节点可以唤醒,返回true以便调用在下一轮循环进入setHeadAndPropagate()方法 if (ws == Node.SIGNAL) /* * This node has already set status asking a release * to signal it, so it can safely park. */ returntrue; // 状态值大于0,说明当前处理的节点的前驱节点处于取消状态,则需要跳过这些取消状态的前驱节点 if (ws > 0) { /* * Predecessor was cancelled. Skip over predecessors and * indicate retry. */ do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { /* * waitStatus must be 0 or PROPAGATE. Indicate that we * need a signal, but don't park yet. Caller will need to * retry to make sure it cannot acquire before parking. */ // 剩下的就是其他情况,初始化状态0或者无条件传播状态Node.PROPAGATE(-3),这两种情况把前驱节点状态CAS更新为Node.SIGNAL(-1),表明当前节点可以被唤醒 pred.compareAndSetWaitStatus(ws, Node.SIGNAL); } returnfalse; }