前提
创业小团队,无论选择任何方案,都优先考虑节省成本。关于分布式定时调度框架,成熟的候选方案有XXL-JOB、Easy Scheduler、Light Task Scheduler和Elastic Job等等,其实这些之前都在生产环境使用过。但是想要搭建高可用的分布式调度平台,这些框架(无论是否去中心化)都需要额外的服务器资源去部署中心调度管理服务实例,甚至有时候还会依赖一些中间件如Zookeeper。回想之前花过一段时间看Quartz的源码去分析它的线程模型,想到了它可以基于MySQL,通过一个不是很推荐的X锁方案(SELECT FOR UPDATE加锁)实现服务集群中单个触发器只有一个节点(加锁成功的那个节点)能够执行,这样子,就能够仅仅依赖于现有的MySQL实例资源实现分布式调度任务管理。一般来说,有关系型数据保存需求的业务应用都会有自己的MySQL实例,这样子就能几乎零成本引入一个分布式调度管理模块。某个加班的周六下午敲定了初步方案之后,花了几个小时把这个轮子造出来了,效果如下:
方案设计
先说说用到的所有依赖:
Uikit:选用的前端的一个轻量级的UI框架,主要是考虑到轻量、文档和组件相对齐全。JQuery:选用js框架,原因只有一个:简单。Freemarker:模板引擎,主观上比Jsp和Thymeleaf好用。Quartz:工业级调度器。
项目的依赖如下:
<dependencies>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<exclusions>
<exclusion>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP-java7</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
|
Uikit和JQuery可以直接使用现成的CDN即可:
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/uikit@3.2.2/dist/css/uikit.min.css"/>
<script src="https://cdn.jsdelivr.net/npm/uikit@3.2.2/dist/js/uikit.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/uikit@3.2.2/dist/js/uikit-icons.min.js"></script>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
|
表设计
引入了Quartz的依赖后,在它的org.quartz.impl.jdbcjobstore包下可以看到一系列的DDL,一般使用MySQL的场景下关注tables_mysql.sql和tables_mysql_innodb.sql两个文件即可,笔者所在团队的开发规范MySQL的引擎必须选择innodb,所以选用了后者。
应用中的定时任务信息应该单独拎出来管理,方便提供统一的查询和更变API。值得注意的是,Quartz内建的表使用了大量的外键,所以尽量通过Quartz提供的API去增删改它内建表的内容,切勿手动操作,否则可能会引发各种意想不到的故障。
引入的两个新的表包括调度任务表schedule_task和调度任务参数表schedule_task_parameter:
CREATE TABLE `schedule_task`
(
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
`creator` VARCHAR(16) NOT NULL DEFAULT 'admin' COMMENT '创建人',
`editor` VARCHAR(16) NOT NULL DEFAULT 'admin' COMMENT '修改人',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`edit_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`version` BIGINT NOT NULL DEFAULT 1 COMMENT '版本号',
`deleted` TINYINT NOT NULL DEFAULT 0 COMMENT '软删除标识',
`task_id` VARCHAR(64) NOT NULL COMMENT '任务标识',
`task_class` VARCHAR(256) NOT NULL COMMENT '任务类',
`task_type` VARCHAR(16) NOT NULL COMMENT '任务类型,CRON,SIMPLE',
`task_group` VARCHAR(32) NOT NULL DEFAULT 'DEFAULT' COMMENT '任务分组',
`task_expression` VARCHAR(256) NOT NULL COMMENT '任务表达式',
`task_description` VARCHAR(256) COMMENT '任务描述',
`task_status` TINYINT NOT NULL DEFAULT 0 COMMENT '任务状态',
UNIQUE uniq_task_class_task_group (`task_class`, `task_group`),
UNIQUE uniq_task_id (`task_id`)
) COMMENT '调度任务';
CREATE TABLE `schedule_task_parameter`
(
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
`task_id` VARCHAR(64) NOT NULL COMMENT '任务标识',
`parameter_value` VARCHAR(1024) NOT NULL COMMENT '参数值',
UNIQUE uniq_task_id (`task_id`)
) COMMENT '调度任务参数';
|
参数统一用JSON字符串存放,所以一个调度任务实体对应0或者1个调度任务参数实体。这里没有考虑多个应用使用同一个数据源的问题,其实这个问题应该考虑基于不同的org.quartz.jobStore.tablePrefix实现隔离,也就是不同的应用如果共库,或者每个应用的Quartz使用不同的表前缀区分,或者单独抽离所有调度任务到同一个应用中。
Quartz的工作模式
Quartz在设计调度模型的时候实际上是对触发器Trigger进行调度,一般在调度对应的任务Job的时候,需要绑定触发器和该被调度的任务实例,然后当触发器到了触发时间点的时候就会被激发,接着回调该触发器关联的Job实例的execute()方法。可以简单理解为触发器和Job实例是多对多的关系。简单来看就是这样的:
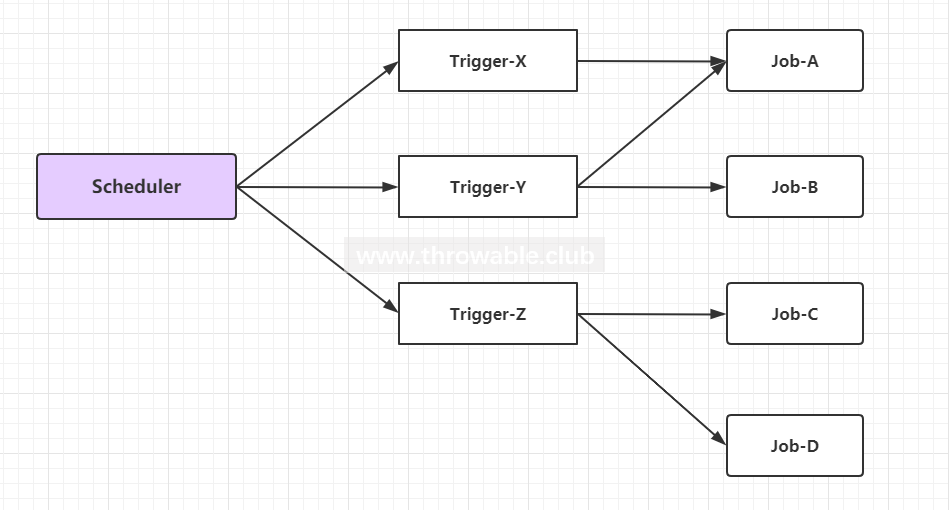
为了实现这个多对多的关系,Quartz为Job(实际上是JobDetail)和Trigger分别定义了JobKey和TriggerKey用于作为两者的唯一标识。
TriggerKey -> [name, group]
JobKey -> [name, group]
|
为了降低维护成本,笔者把这个多对多的绑定关系强制约束为一对一,并且把TriggerKey和JobKey同化如下:
JobKey,TriggerKey -> [jobClassName, ${spring.application.name} || applicationName]
|
实际上,调度相关的大部分工作都是委托给org.quartz.Scheduler完成,举下例子:
public interface Scheduler {
......省略无关的代码......
void scheduleJob(JobDetail jobDetail, Set<? extends Trigger> triggersForJob, boolean replace) throws SchedulerException;
boolean unscheduleJob(TriggerKey triggerKey) throws SchedulerException;
boolean deleteJob(JobKey jobKey) throws SchedulerException;
......省略无关的代码......
}
|
笔者要做的,就是通过schedule_task表管理服务的定时任务,通过org.quartz.Scheduler提供的API把任务的具体操作移交给Quartz,并且添加一些扩展功能。这个模块已经被封装为一个轻量级的框架,命名为quartz-web-ui-kit,下称kit。
kit核心逻辑分析
kit的所有核心功能都封装在模块quartz-web-ui-kit-core中,主要功能包括:
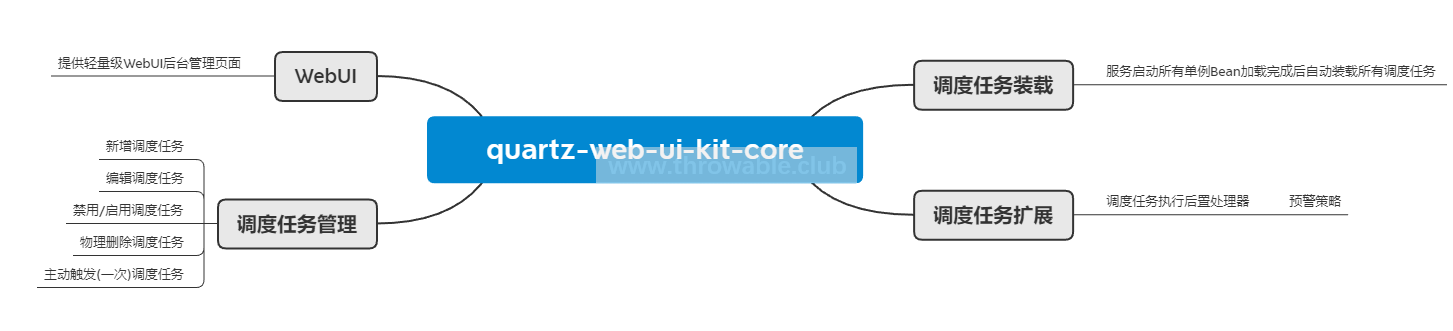
其中WebUI部分是通过Freemarker、JQuery和Uikit简单编写出来,主要包括三个页面:
templates
- common/script.ftl 公共脚本
- task-add.ftl 添加新任务页面
- task-edit.ftl 编辑任务页面
- task-list.ftl 任务列表
|
调度任务管理的核心方法是QuartzWebUiKitService#refreshScheduleTask():
@Autowired
private Scheduler scheduler;
public void refreshScheduleTask(ScheduleTask task,
Trigger oldTrigger,
TriggerKey triggerKey,
Trigger newTrigger) throws Exception {
JobDataMap jobDataMap = prepareJobDataMap(task);
JobDetail jobDetail =
JobBuilder.newJob((Class<? extends Job>) Class.forName(task.getTaskClass()))
.withIdentity(task.getTaskClass(), task.getTaskGroup())
.usingJobData(jobDataMap)
.build();
if (ScheduleTaskStatus.ONLINE == ScheduleTaskStatus.fromType(task.getTaskStatus())) {
scheduler.scheduleJob(jobDetail, Collections.singleton(newTrigger), Boolean.TRUE);
} else {
if (null != oldTrigger) {
scheduler.unscheduleJob(triggerKey);
}
}
}
private JobDataMap prepareJobDataMap(ScheduleTask task) {
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("scheduleTask", JsonUtils.X.format(task));
ScheduleTaskParameter taskParameter = scheduleTaskParameterDao.selectByTaskId(task.getTaskId());
if (null != taskParameter) {
Map<String, Object> parameterMap = JsonUtils.X.parse(taskParameter.getParameterValue(),
new TypeReference<Map<String, Object>>() {
});
jobDataMap.putAll(parameterMap);
}
return jobDataMap;
}
|
其实是任意任务触发或者变动,都直接覆盖对应的JobDetail和Trigger,这样就能保证调度任务内容和触发器都是全新的,下一轮调度就会生效。
任务类被抽象为AbstractScheduleTask,这个类承载了任务执行和大量的扩展功能:
@DisallowConcurrentExecution
public abstract class AbstractScheduleTask implements Job {
protected Logger logger = LoggerFactory.getLogger(getClass());
@Autowired(required = false)
private List<ScheduleTaskExecutionPostProcessor> processors;
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
String scheduleTask = context.getMergedJobDataMap().getString("scheduleTask");
ScheduleTask task = JsonUtils.X.parse(scheduleTask, ScheduleTask.class);
ScheduleTaskInfo info = ScheduleTaskInfo.builder()
.taskId(task.getTaskId())
.taskClass(task.getTaskClass())
.taskDescription(task.getTaskDescription())
.taskExpression(task.getTaskExpression())
.taskGroup(task.getTaskGroup())
.taskType(task.getTaskType())
.build();
long start = System.currentTimeMillis();
info.setStart(start);
MappedDiagnosticContextAssistant.X.processInMappedDiagnosticContext(() -> {
try {
if (enableLogging()) {
logger.info("任务[{}]-[{}]-[{}]开始执行......", task.getTaskId(), task.getTaskClass(), task.getTaskDescription());
}
processBeforeTaskExecution(info);
executeInternal(context);
processAfterTaskExecution(info, ScheduleTaskExecutionStatus.SUCCESS);
} catch (Exception e) {
info.setThrowable(e);
if (enableLogging()) {
logger.info("任务[{}]-[{}]-[{}]执行异常", task.getTaskId(), task.getTaskClass(),
task.getTaskDescription(), e);
}
processAfterTaskExecution(info, ScheduleTaskExecutionStatus.FAIL);
} finally {
long end = System.currentTimeMillis();
long cost = end - start;
info.setEnd(end);
info.setCost(cost);
if (enableLogging() && null != info.getThrowable()) {
logger.info("任务[{}]-[{}]-[{}]执行完毕,耗时:{} ms......", task.getTaskId(), task.getTaskClass(),
task.getTaskDescription(), cost);
}
processAfterTaskCompletion(info);
}
});
}
protected boolean enableLogging() {
return true;
}
protected abstract void executeInternal(JobExecutionContext context);
private ScheduleTaskInfo copyScheduleTaskInfo(ScheduleTaskInfo info) {
return ScheduleTaskInfo.builder()
.cost(info.getCost())
.start(info.getStart())
.end(info.getEnd())
.throwable(info.getThrowable())
.taskId(info.getTaskId())
.taskClass(info.getTaskClass())
.taskDescription(info.getTaskDescription())
.taskExpression(info.getTaskExpression())
.taskGroup(info.getTaskGroup())
.taskType(info.getTaskType())
.build();
}
void processBeforeTaskExecution(ScheduleTaskInfo info) {
if (null != processors) {
for (ScheduleTaskExecutionPostProcessor processor : processors) {
processor.beforeTaskExecution(copyScheduleTaskInfo(info));
}
}
}
void processAfterTaskExecution(ScheduleTaskInfo info, ScheduleTaskExecutionStatus status) {
if (null != processors) {
for (ScheduleTaskExecutionPostProcessor processor : processors) {
processor.afterTaskExecution(copyScheduleTaskInfo(info), status);
}
}
}
void processAfterTaskCompletion(ScheduleTaskInfo info) {
if (null != processors) {
for (ScheduleTaskExecutionPostProcessor processor : processors) {
processor.afterTaskCompletion(copyScheduleTaskInfo(info));
}
}
}
}
|
需要执行的目标调度任务类只需要继承AbstractScheduleTask即可获得这些功能。另外,调度任务后置处理器ScheduleTaskExecutionPostProcessor参考了Spring中的BeanPostProcessor和TransactionSynchronization的设计:
public interface ScheduleTaskExecutionPostProcessor {
default void beforeTaskExecution(ScheduleTaskInfo info) {
}
default void afterTaskExecution(ScheduleTaskInfo info, ScheduleTaskExecutionStatus status) {
}
default void afterTaskCompletion(ScheduleTaskInfo info) {
}
}
|
通过此后置处理器可以完成任务预警和任务执行日志持久化等各种功能。笔者通过ScheduleTaskExecutionPostProcessor已经实现了内置的预警功能,抽象出一个预警策略接口AlarmStrategy:
public interface AlarmStrategy {
void process(ScheduleTaskInfo scheduleTaskInfo);
}
public class NoneAlarmStrategy implements AlarmStrategy {
@Override
public void process(ScheduleTaskInfo scheduleTaskInfo) {
}
}
|
通过覆盖AlarmStrategy的Bean配置即可获得自定义的预警策略,如:
@Slf4j
@Component
public class LoggingAlarmStrategy implements AlarmStrategy {
@Override
public void process(ScheduleTaskInfo scheduleTaskInfo) {
if (null != scheduleTaskInfo.getThrowable()) {
log.error("任务执行异常,任务内容:{}", JsonUtils.X.format(scheduleTaskInfo), scheduleTaskInfo.getThrowable());
}
}
}
|
笔者通过此接口的自定义现实,把所有的预警都打印到团队内部的钉钉群中,打印了任务的执行时间、状态以及耗时等等信息,一旦出现异常会及时@所有人,便于及时监控任务的健康和后续的调优。
使用kit项目
quartz-web-ui-kit的项目结构如下:
quartz-web-ui-kit
- quartz-web-ui-kit-core 核心包
- h2-example H2数据库的演示例子
- mysql-5.x-example MySQL5.x版本的演示例子
- mysql-8.x-example MySQL8.x版本的演示例子
|
如果单纯想体验一下kit的功能,那么直接下载此项目,启动h2-example模块中的club.throwable.h2.example.H2App,然后访问http://localhost:8081/quartz/kit/task/list即可。
基于MySQL实例的应用,这里挑选目前用户比较多的MySQL5.x的例子简单说明一下。因为轮子刚造好,没有经过时间的考验,暂时没上交到Maven的仓库,这里需要进行手动编译:
git clone https://github.com/zjcscut/quartz-web-ui-kit
cd quartz-web-ui-kit
mvn clean compile install
|
引入依赖(只需要引入quartz-web-ui-kit-core,而且quartz-web-ui-kit-core依赖于spring-boot-starter-web、spring-boot-starter-web、spring-boot-starter-jdbc、spring-boot-starter-freemarker和HikariCP):
<dependency>
<groupId>club.throwable</groupId>
<artifactId>quartz-web-ui-kit-core</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
|
添加一个配置实现QuartzWebUiKitConfiguration:
@Configuration
public class QuartzWebUiKitConfiguration implements EnvironmentAware {
private Environment environment;
@Override
public void setEnvironment(Environment environment) {
this.environment = environment;
}
@Bean
public QuartzWebUiKitPropertiesProvider quartzWebUiKitPropertiesProvider() {
return () -> {
QuartzWebUiKitProperties properties = new QuartzWebUiKitProperties();
properties.setDriverClassName(environment.getProperty("spring.datasource.driver-class-name"));
properties.setUrl(environment.getProperty("spring.datasource.url"));
properties.setUsername(environment.getProperty("spring.datasource.username"));
properties.setPassword(environment.getProperty("spring.datasource.password"));
return properties;
};
}
}
|
这里由于quartz-web-ui-kit-core设计时候考虑到部分组件的加载顺序,使用了ImportBeanDefinitionRegistrar钩子接口,所以无法通过@Value或者@Autowired实现属性注入,因为这两个注解的处理顺序比较靠后,如果用过MyBatis的MapperScannerConfigurer就会理解这里的问题。quartz-web-ui-kit-core依赖中已经整理好一份DDL脚本:
scripts
- quartz-h2.sql
- quartz-web-ui-kit-h2-ddl.sql
- quartz-mysql-innodb.sql
- quartz-web-ui-kit-mysql-ddl.sql
|
需要提前在目标数据库执行quartz-mysql-innodb.sql和quartz-web-ui-kit-mysql-ddl.sql。一份相对标准的配置文件application.properties如下:
spring.application.name=mysql-5.x-example
server.port=8082
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/local?characterEncoding=utf8&useUnicode=true&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
spring.freemarker.template-loader-path=classpath:/templates/
spring.freemarker.cache=false
spring.freemarker.charset=UTF-8
spring.freemarker.check-template-location=true
spring.freemarker.content-type=text/html
spring.freemarker.expose-request-attributes=true
spring.freemarker.expose-session-attributes=true
spring.freemarker.request-context-attribute=request
spring.freemarker.suffix=.ftl
|
然后需要添加一个调度任务类,只需要继承club.throwable.quartz.kit.support.AbstractScheduleTask:
@Slf4j
public class CronTask extends AbstractScheduleTask {
@Override
protected void executeInternal(JobExecutionContext context) {
logger.info("CronTask触发,TriggerKey:{}", context.getTrigger().getKey().toString());
}
}
|
接着启动SpringBoot的启动类,然后访问http://localhost:8082/quartz/kit/task/list:
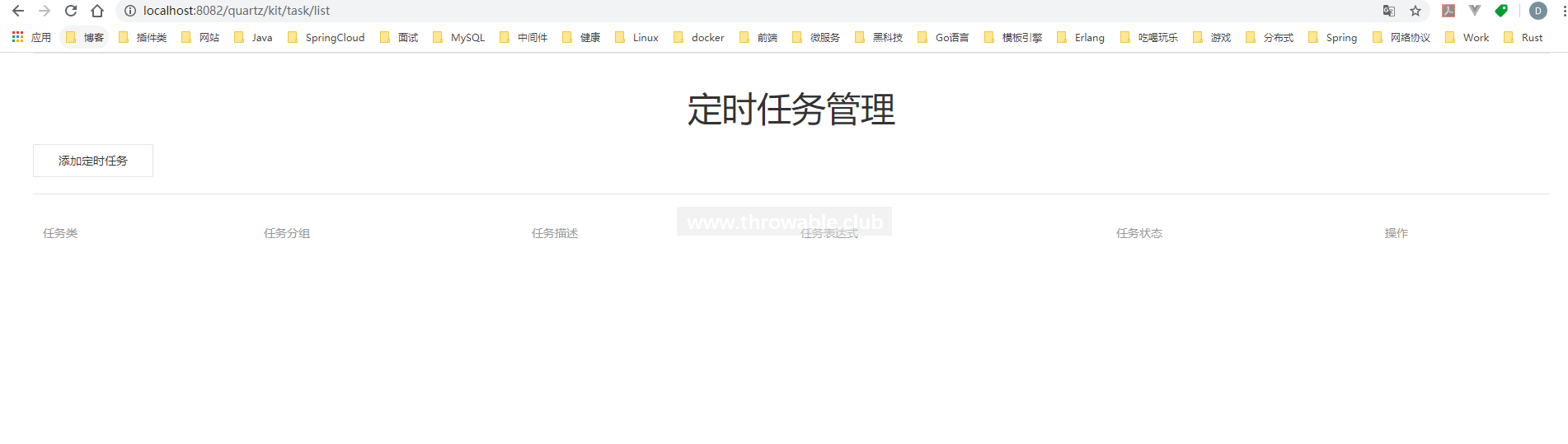
通过左侧按钮添加一个定时任务:
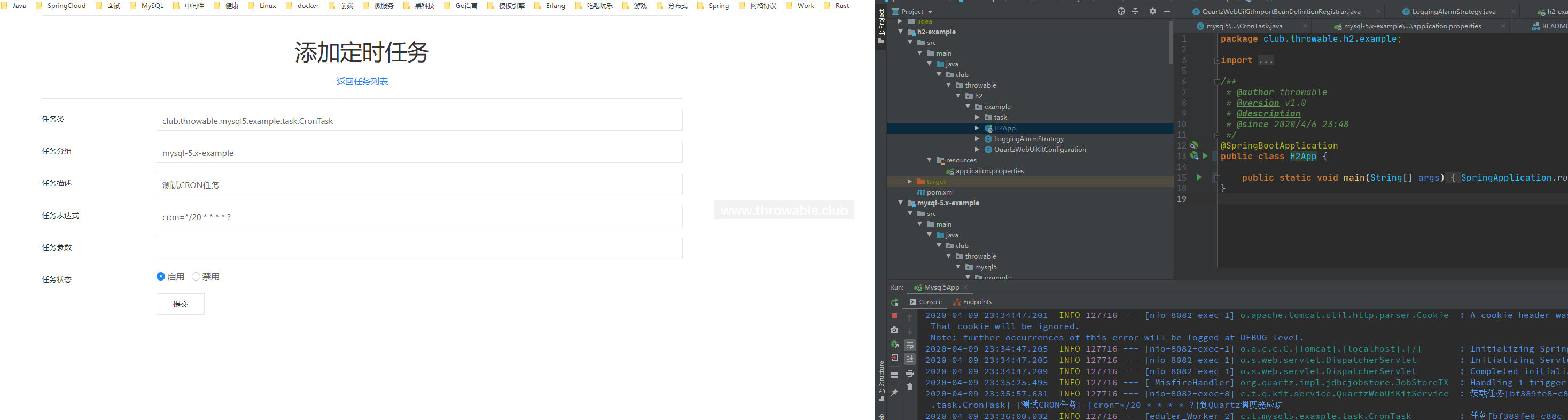
目前的任务表达式支持两种类型:
CRON表达式:格式是cron=你的CRON表达式,如cron=*/20 * * * * ?。- 简单的周期性执行表达式:格式是
intervalInMilliseconds=毫秒值,如intervalInMilliseconds=10000,表示10000毫秒执行一次。
其他可选的参数有:
repeatCount:表示简单的周期性执行任务的重复次数,默认为Integer.MAX_VALUE。startAt:任务首次执行的时间戳。
关于任务表达式参数,没有考虑十分严格的校验,也没有做字符串的trim处理,需要输入紧凑的符合约定格式的特定表达式,如:
cron=*/20 * * * * ?
intervalInMilliseconds=10000
intervalInMilliseconds=10000,repeatCount=10
|
调度任务还支持输入用户的自定义参数,目前简单约定为JSON字符串,这个字符串最后会通过Jackson进行一次处理,再存放到任务的JobDataMap中,实际上会被Quartz持久化到数据库中:
这样就能从JobExecutionContext#getMergedJobDataMap()中获得,例如:
@Slf4j
public class SimpleTask extends AbstractScheduleTask {
@Override
protected void executeInternal(JobExecutionContext context) {
JobDataMap jobDataMap = context.getMergedJobDataMap();
String value = jobDataMap.getString("key");
}
}
|
其他
关于kit,有两点设计是笔者基于团队中维护的项目面对的场景做了特化处理:
AbstractScheduleTask使用了@DisallowConcurrentExecution注解,任务会禁用并发执行,也就是多节点的情况下,只会有一个服务节点在同一轮触发时间下进行任务调度。CRON类型的任务被禁用了Misfire策略,也就是CRON类型的任务如果错失了触发时机不会有任何操作(这一点可以了解一下Quartz的Misfire策略)。
如果不能忍受这两点,切勿直接在生产中使用此工具包。
小结
本文简单介绍了笔者通过Quartz的加持造了一个轻量级分布式调度服务的轮子,起到了简单易用和节省成本的效果。不足的是,因为考虑到目前团队的项目中存在调度任务需求的服务都是内部的共享服务,笔者没有花很大的精力去完善鉴权、监控等模块,这里也是也是从目前遇到的业务场景考虑,如果引入过多的设计,就会演化成一个重量级的调度框架如Elastic-Job,那样会违背了节省部署成本的初衷。
(本文完 c-14-d e-a-20200410 最近太忙这个文章憋了很久……)











